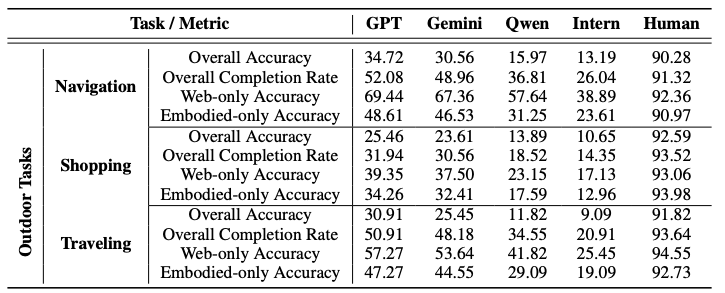
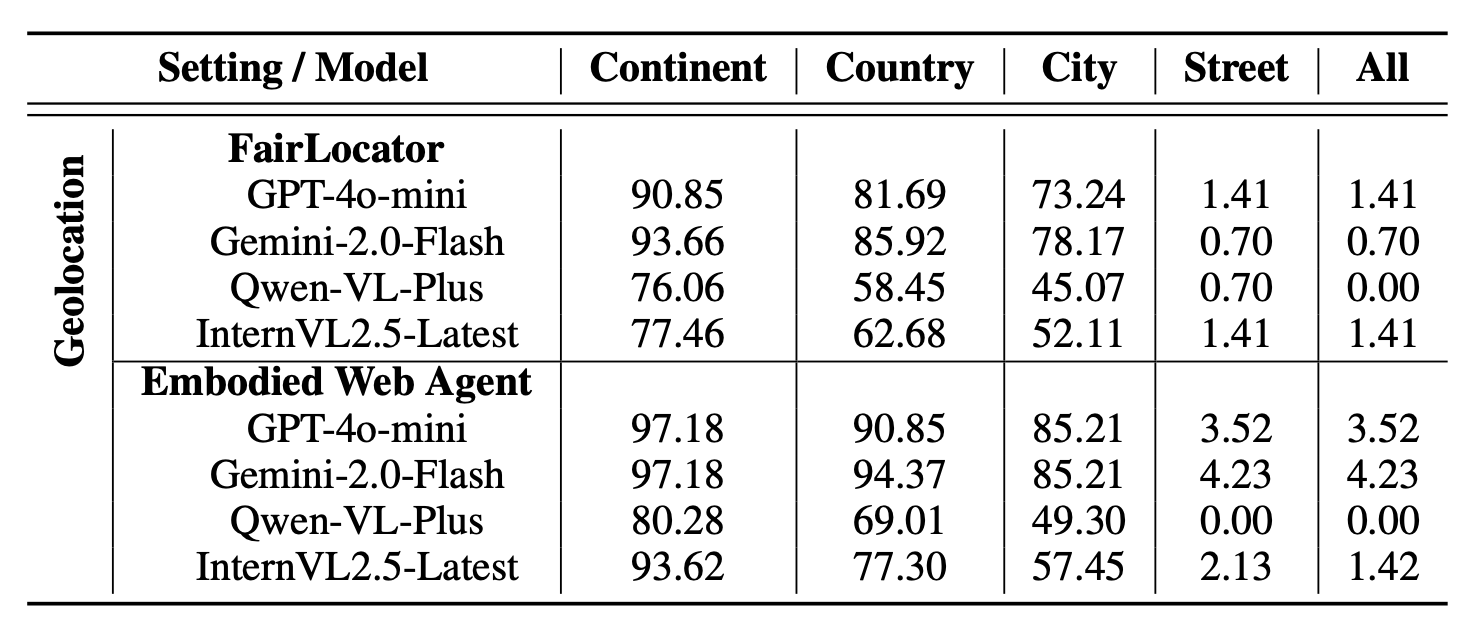
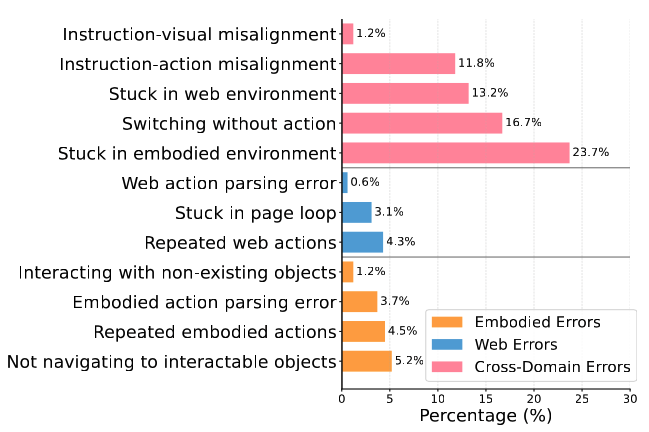
To operationalize this concept, we first develop the Embodied Web Agents task environments, a unified simulation platform that integrates realistic 3D environments with interactive web interfaces.
Indoor Settings
Realistic 3D indoor environments from AI2-THOR for embodied interaction and navigation.
Outdoor Navigation
Google Earth integration for large-scale outdoor exploration and wayfinding tasks.
Web Interfaces
Interactive web platforms including Wikipedia, online stores, recipe websites, and map services.